

Just released: interactive workflows, incidents, new compute options, and much more
Stop wondering about your workflows
The orchestrator for people who have done orchestration before
1from prefect import flow, task
2
3
4@task(log_prints=True)
5def say_hello(name: str):
6 print(f"Hello {name}!")
7
8
9@flow
10def hello_universe(names: list[str]):
11 for name in names:
12 say_hello(name)
13
14
15if __name__ == "__main__":
16 # create your first deployment to automate your flow
17 hello_universe.serve(name="your-first-deployment")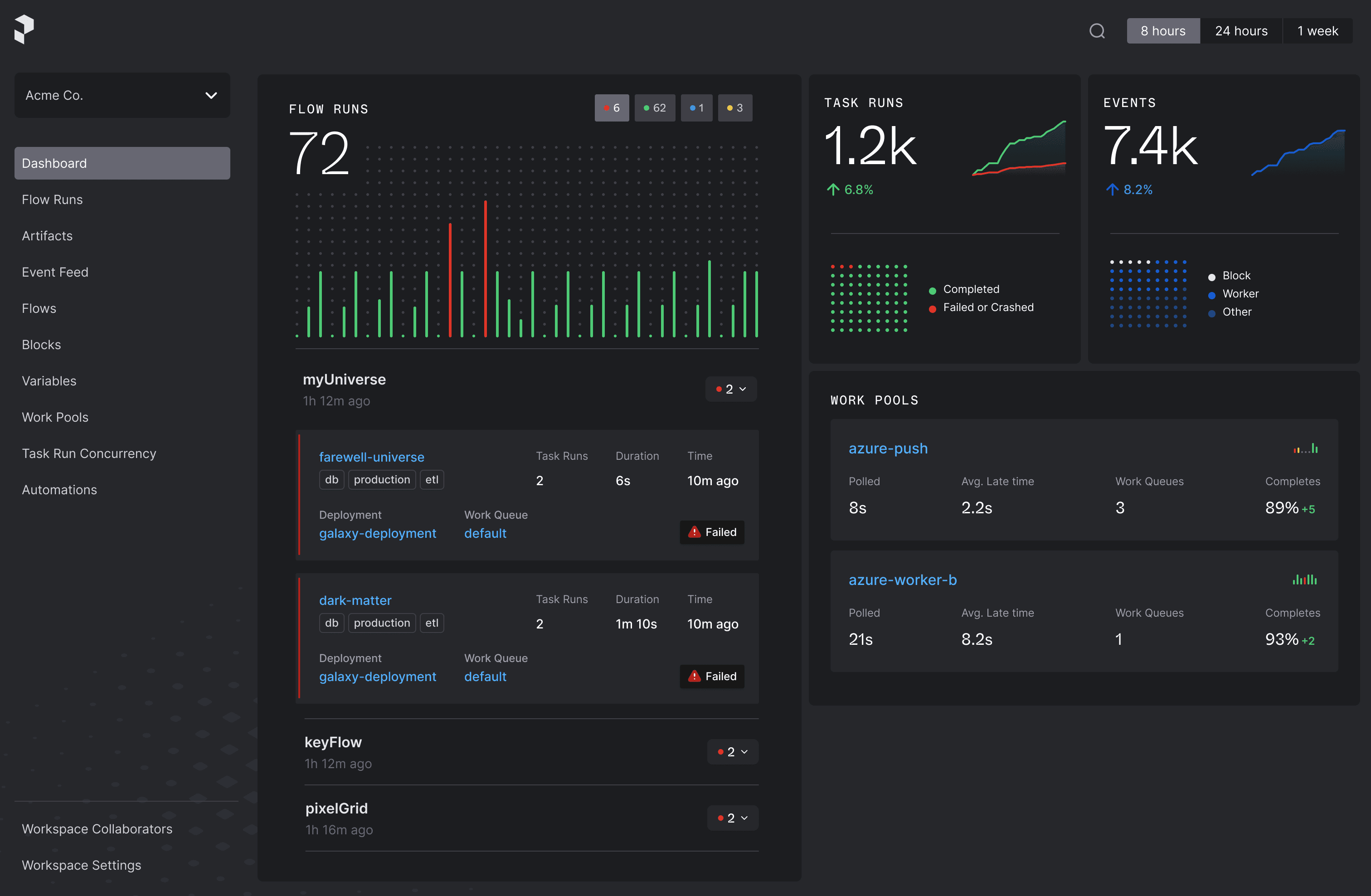
Modern workflow orchestration for data and ML engineers





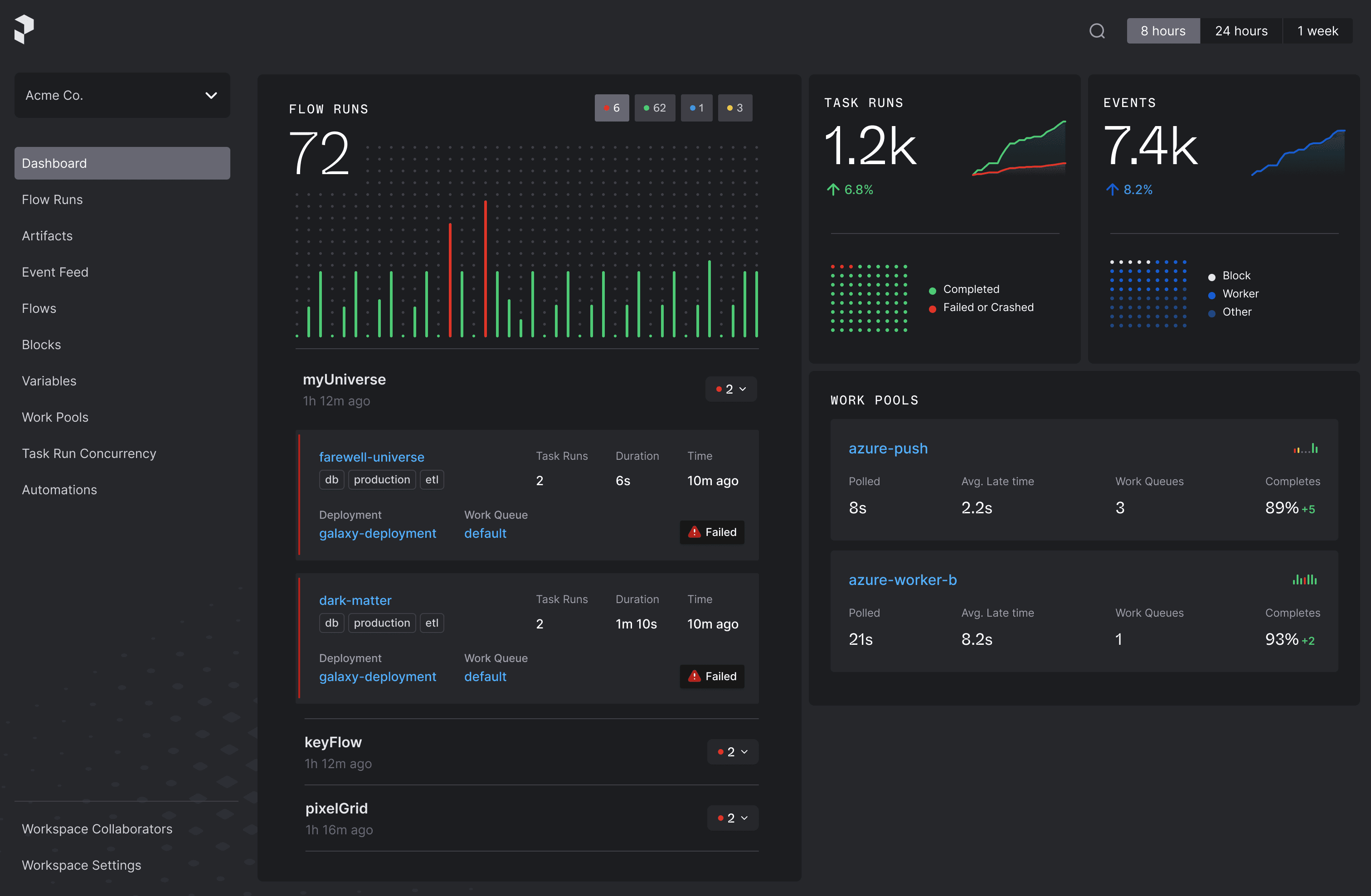
Control panel for your workflows
Orchestrate your code with scheduling, automatic retries, and prioritized instant alerting, giving you full observability into your workflows.

Pure Python
You bring raw Python functions, Prefect handles the rest. No more boilerplate code.
- if statements
- for and while loops
- native subflows

1from prefect import flow, task
2
3@task
4def add_one(x: int):
5 return x + 1
6
7@flow
8def main():
9 for x in [1, 2, 3]:
10 first = add_one(x)
11 second = add_one(first)Recover quickly
With custom retry behavior, caching, and extensive automations, go from red to green in minutes instead of days.
Easy local development
Start a local test server with a single command,
and test your work without pain.

1from prefect import flow
2
3@flow
4def say_hi():
5 print("Hi, I'm a Prefect flow!")
6
7if __name__ == "__main__":
8 say_hi.serve(name="my-deployment")Your flow 'say-hi' is being served and polling for scheduled runs!
To trigger a run for this flow, use the following command:
$ prefect deployment run 'say-hi/my-deployment' Choose your own infrastructure
Configure your execution environment, all the way down to the individual @flow.
With work pools and work queues, you have granular control over your infrastructure.
1# flow.py
2import os
3from prefect import flow
4
5@flow
6def main():
7 if os.cpu_count() <= 2:
8 print("💪")
9 else:
10 print("💪💪💪")# Deploy to Kubernetes
prefect deploy flow.py:flow --pool kubernetes
# Deploy to staging server
prefect deploy flow.py:flow --pool process-stagingSee Your Whole Stack
Look inside your pipelines with events from any third party tool.
What developers are saying

Saving us days on DAG design vs. Airflow

Okay, Prefect is officially awesome. I just launched the server locally and realized i didn’t see the whole picture from the docs. Thanks for building such an amazing product.

Underrated @PrefectIO use-case of the day: ... observability and retries! Prefect is not only a "scheduler". By adding a flow/task decorator, you can add observability to your python scripts.

Our critical bug rate has dropped by 65% since we’ve implemented Prefect
Our previous architecture took 24 hours to run the models. With Prefect, it's 3.
Hello, Currently scoping out using Prefect for our orchestration. Thanks for the great project. :)
Prefect Core provides a really nice, clean set of easy to use features for constructing data pipelines (Tasks, Flows, States, Results) and it’s easy to model the dependencies between tasks.
• Airflow has a steeper learning curve. Team struggled.
• @PrefectIO is more Pythonic and team picked it up quite easily
• Cloud version has a generous free-tier. Lesser friction to get started.
Invest heavily in Automation early on. If you do things twice, automate it, or at least document it. @PrefectIO is free and easy to set up, it`ll be the reliable backbone of your business automations
We used to spend 20% of our time (and up to 80% at times) on errors. With Prefect, we're approaching 5%, a 75% reduction.