
Why Not Airflow?
Airflow is a historically important tool in the data engineering ecosystem, and we have spent a great deal of time working on it. It introduced the ability to combine a strict Directed Acyclic Graph (DAG) model with Pythonic flexibility in a way that made it appropriate for a wide variety of use cases. However, Airflow’s applicability is limited by its legacy as a monolithic batch scheduler aimed at data engineers principally concerned with orchestrating third-party systems employed by others in their organizations.
Today, many data engineers are working more directly with their analytical counterparts. Compute and storage are cheap, so friction is low and experimentation prevails. Processes are fast, dynamic, and unpredictable. Airflow got many things right, but its core assumptions never anticipated the rich variety of data applications that has emerged. It simply does not have the requisite vocabulary to describe many of those activities.
The seed that would grow into Prefect was first planted all the way back in 2016, in a series of discussions about how Airflow would need to change to support what were rapidly becoming standard data practices. Disappointingly, those observations remain valid today. We open sourced the Prefect engine a few weeks ago as the first step toward introducing a modern data platform, and we’re extremely encouraged by the early response!
We know that questions about how Prefect compares to Airflow are paramount to our users, especially given Prefect’s lineage. We prepared this document to highlight common Airflow issues that the Prefect engine takes specific steps to address. This post is not intended to be an exhaustive tour of Prefect’s features, but rather a guide for users familiar with Airflow that explains Prefect’s analogous approach. We have tried to be balanced and limit discussion of anything not currently available in our open-source repo, and we hope this serves as a helpful overview for the community.
Happy engineering!
Table of Contents
- Overview
- API
- Scheduling and Time
- The Scheduler Service
- Dataflow
- Parametrized Workflows
- Dynamic Workflows
- Versioned Workflows
- Local Testing
- UI
- Conclusions
Overview
Airflow was designed to run static, slow-moving workflows on a fixed schedule, and it is a great tool for that purpose. Airflow was also the first successful implementation of workflows-as-code, a useful and flexible paradigm. It proved that workflows could be built without resorting to config files or obtuse DAG definitions.
However, because of the types of workflows it was designed to handle, Airflow exposes a limited “vocabulary” for defining workflow behavior, especially by modern standards. Users often get into trouble by forcing their use cases to fit into Airflow’s model. A sampling of examples that Airflow can not satisfy in a first-class way includes:
- DAGs which need to be run off-schedule or with no schedule at all
- DAGs that run concurrently with the same start time
- DAGs with complicated branching logic
- DAGs with many fast tasks
- DAGs which rely on the exchange of data
- Parametrized DAGs
- Dynamic DAGs
If your use case resembles any of these, you will need to work around Airflow’s abstractions rather than with them. For this reason, almost every medium-to-large company using Airflow ends up writing a custom DSL or maintaining significant proprietary plugins to support its internal needs. This makes upgrading difficult and dramatically increases the maintenance burden when anything breaks.
Prefect is the result of years of experience working on Airflow and related projects. Our research, spanning hundreds of users and companies, has allowed us to discover the hidden pain points that current tools fail to address. It has culminated in an incredibly user-friendly, lightweight API backed by a powerful set of abstractions that fit most data-related use cases.
API
When workflows are defined as code, they become more maintainable, versionable, testable, and collaborative.
Production workflows are a special creature — they typically involve multiple stakeholders across the technical spectrum, and are usually business critical. For this reason, it is important that your workflow system be as simple and expressive as it can possibly be. Given its popularity and omnipresence in the data stack, Python is a natural choice for the language of workflows. Airflow was the first tool to take this to heart, and actually implement its API in Python.
However, Airflow’s API is fully imperative and class-based. Additionally, because of the constraints that Airflow places on what workflows can and cannot do (expanded upon in later sections), writing Airflow DAGs feels like writing Airflow code.
One of Prefect’s fundamental insights is that if you could guarantee your code would run as intended, you wouldn’t need a workflow system at all. It’s only when things go wrong that workflow management is critical. In this light, workflow systems are risk management tools (we’ve written about this before) and, when well designed, should stay out of users’ way until they’re needed.
Therefore, Prefect’s design goal is to be minimally invasive when things go right and maximally helpful when they go wrong. Either way, the system can provide the same level of transparency and detail for your workflows.
One way we achieve this is through our “functional API.” In this mode, Prefect tasks behave just like functions. You can call them with inputs and work with their outputs —you can even convert any Python function to a task with one line of Prefect code. Calling tasks on each other like functions builds the DAG in a natural, Pythonic way. This makes converting existing code or scripts into full-fledged Prefect workflows a trivial exercise.
Not to worry, Prefect also exposes a full imperative API that will be familiar to Airflow users. The imperative API is useful for specifying more complex task dependencies, or for more explicit control. Users can switch between the two styles at any time depending on their needs and preferences.
Scheduling and Time
Time is an illusion. Lunchtime doubly so.
Perhaps the most common confusion amongst newcomers to Airflow is its use of time. For example, were you to run the Airflow tutorial, you might find yourself running:
and wondering what all these different times mean.
Airflow has a strict dependency on a specific time: the execution_date. No DAG can run without an execution date, and no DAG can run twice for the same execution date. Do you have a specific DAG that needs to run twice, with both instantiations starting at the same time? Airflow doesn’t support that; there are no exceptions. Airflow simply decrees that such workflows do not exist. You’ll need to create two nearly-identical DAGs, or start them a millisecond apart, or employ other creative hacks to get this to work.
More confusingly, the execution_date is not interpreted by Airflow as the start time of the DAG, but rather the end of an interval capped by the DAG’s start time. This was originally due to ETL orchestration requirements, where the job for May 2nd’s data would be run on May 3rd. Today, it is a source of major confusion and one of the most common misunderstandings new users have.
This interval notion arises from Airflow’s strict requirement that DAGs have well-defined schedules. Until recently, it was not even possible to run a DAG off-schedule — the scheduler would get confused by the off-schedule run and schedule future runs at the wrong time! Ad-hoc runs are now possible as long as they don’t share an execution_date with any other run.
This means that if you want to:
- run your workflow on an irregular (or no) schedule
- run multiple simultaneous runs of your workflow
- maintain a workflow that only runs manually
then Airflow is the wrong tool.
Prefect
In contrast, Prefect treats workflows as standalone objects that can be run any time, with any concurrency, for any reason. A schedule is nothing more than a predefined set of start times, and you can make your schedules as simple or as complex as you want. And if you do want your workflow to depend on time, simply add it as a flow parameter.
The Scheduler Service
R2-D2, you know better than to trust a strange computer!
The Airflow Scheduler is the backbone of Airflow. This service is critical to the performance of Airflow and is responsible for:
- reparsing the DAG folder every few seconds
- checking DAG schedules to determine if a DAG is ready to run
- checking all Task dependencies to determine if any Tasks are ready to be run
- setting the final DAG states in the database
Conversely, Prefect decouples most of this logic into separate (optional) processes:
Prefect Flow scheduling
Scheduling a flow in Prefect is a lightweight operation. We simply create a new flow run and place it in a Scheduled state. In fact, when we talk about Prefect Cloud’s “scheduler,” that is its sole responsibility. Our scheduler never gets involved in any workflow logic or execution.
Prefect Flow logic
Prefect Flows themselves are standalone units of workflow logic. There is no reason for a scheduler to ever parse them or interact with the resulting states.
As proof, you can run an entire flow in your local process with no additional overhead:
Prefect Task scheduling
When a Prefect flow runs, it handles scheduling for its own tasks. This is important for a few reasons:
- As the source of workflow logic, the flow is the only object that should have this responsibility.
- It takes an enormous burden off the central scheduler.
- It lets the flow make decisions about unique circumstances like dynamically-generated tasks (that result from Prefect’s map operator, for example)
- It lets Prefect outsource details of execution to external systems like Dask.
This last point is important. While Airflow has support for a variety of execution environments, including local processes, Celery, Dask, and Kubernetes, it remains bottlenecked by its own scheduler, which (with default settings) takes 10 seconds to run any task (5 seconds to mark it as queued, and 5 seconds to submit it for execution). No matter how big your Dask cluster, Airflow will still only ask it to run a task every 10 seconds.
Prefect, in contrast, embraces modern technology. When you run Prefect on Dask, we take advantage of Dask’s millisecond-latency task scheduler to run all tasks as quickly as possible, with as much parallelism as the cluster offers (we’ve written about that, too!). Indeed, the default deployment specification for Prefect Cloud deploys Dask clusters in Kubernetes (this is also customizable).
Besides performance, this has a major implication for how flows are designed: Airflow encourages “large” tasks; Prefect encourages smaller, modular tasks (and can still handle large ones).
Furthermore, when running a flow on Prefect Cloud or with a custom database, Task and Flow Runners are responsible for updating database state, not the scheduler.
Summary
- the centralized Airflow scheduler loop introduces non-trivial latency between when a Task’s dependencies are met and when that Task begins running. If your use case involves few long-running Tasks, this is completely fine — but if you want to execute a DAG with many tasks or where time is of the essence, this could quickly lead to a bottleneck.
- Airflow’s tight coupling of time and schedules with workflows also means that you need to instantiate both a database and a scheduler service in order to run your DAGs locally. These are clearly necessary features of a production environment, but can be burdensome when trying to test and iterate quickly.
- the centralized nature of the Airflow scheduler provides a single point of failure for the system
- reparsing the DAG with every single loop can lead to major inconsistencies (it’s possible for the scheduler to run a task which, when it reinstantiates itself, discovers it doesn’t even exist!)
- central scheduling typically means tasks can’t communicate with each other (no dependency resolution)
Dataflow
It’s a trap!
One of the most common uses of Airflow is to build some sort of data pipeline, which is ironic because Airflow does not support dataflow in a first class way.
What Airflow does offer is an “XCom,” a utility that was introduced to allow tasks to exchange small pieces of metadata. This is a useful feature if you want task A to tell task B that a large dataframe was written to a known location in cloud storage. However, it has become a major source of Airflow errors as users attempt to use it as a proper data pipeline mechanism.
XComs use admin access to write executable pickles into the Airflow metadata database, which has security implications. Even in JSON form, it has immense data privacy issues. This data has no TTL or expiration, which creates performance and cost issues. Most critically, the use of XComs creates strict upstream/downstream dependencies between tasks that Airflow (and its scheduler) know nothing about! If users don’t take additional care, Airflow may actually run these tasks in the wrong order. Consider the following pattern:
This task explicitly depends on an action taken by a “push” task, but Airflow has no way of knowing this. If the user doesn’t explicitly (and redundantly) make that clear to Airflow, then the scheduler may run these tasks out of order. Even if the user does tell Airflow about the relationship, Airflow has no way of understanding that it’s a data-based relationship, and will not know what to do if the XCom push fails. This is one of the most common but subtle and difficult-to-debug classes of Airflow bugs.
An unfortunately frequent outcome for Airflow novices is that they kill their metadata database through XCom overuse. We’ve seen cases where someone created a modest (10GB) dataframe and used XComs to pass it through a variety of tasks. If there are 10 tasks, then every single run of this DAG writes 100GB of permanent data to Airflow’s metadata database.
Prefect
Prefect elevates dataflow to a first class operation. Tasks can receive inputs and return outputs, and Prefect manages this dependency in a transparent way. Additionally, Prefect almost never writes this data into its database; instead, the storage of results (only when required) is managed by secure “result handlers” that users can easily configure. This provides many benefits:
- users can write code using familiar Python patterns
- dependencies cannot be sidestepped, because they are known to the engine. This provide a more transparent debugging experience
- Airflow-style patterns without dependencies are still supported (and sometimes encouraged!); just because Prefect allows for dataflow, doesn’t mean you have to use it!
- because Tasks can directly exchange data, Prefect can support more complicated branching logic, richer Task states, and enforce a stricter contract between Tasks and Runners within a Flow (e.g., a Task cannot alter its downstream Tasks states in the database)
Parametrized Workflows
I’m sorry Dave, I’m afraid I can’t do that.
It’s often convenient to have a workflow that is capable of handling or responding to different inputs. For example, a workflow might represent a series of steps that could be repeated for information coming from different APIs, databases, or IDs — all of which reuse the same processing logic. Alternatively, you might want to use an input parameter to affect the workflow processing itself.
Because Airflow DAGs are supposed to run on fixed schedules and not receive inputs, this is not a “first class” pattern in Airflow. Of course, it is possible to work around this restriction, but the solutions typically involve “hijacking” the fact that the Airflow scheduler reparses DAG files continually and using an Airflow Variable that the DAG file dynamically responds to. If you must resort to taking advantage of the scheduler’s internal implementation details, you’re probably doing something wrong.
Prefect
Prefect offers a convenient abstraction for such situations: that of a Parameter. Parameters in Prefect are a special type of Task whose value can be (optionally) overridden at runtime. For example, locally we could have:
When running in deployment with Prefect Cloud, parameter values can be provided via simple GraphQL calls or using Prefect’s Python Client.
This provides many benefits:
- a much more transparent data lineage for when things go wrong
- you don’t need to create new workflows for different parameter values, only new workflow runs
- allows you to setup workflows that respond to events, and the workflow can follow different branches depending on the type or content of the event
Earlier, we noted that Airflow didn’t even have a concept of running a workflow simultaneously, which is partially related to the fact that it doesn’t have a notion of parameters. When workflows can’t respond to inputs, it doesn’t make as much sense to run multiple instances simultaneously.
However, with first-class parametrization, it’s quite easy to understand why I might want to run multiple instances of a workflow at the same time — to send multiple emails, or update multiple models, or any set of activities where the workflow logic is the same but an input value might differ.
Dynamic Workflows
You’re gonna need a bigger boat.
In addition to parametrized workflows, it is often the case that within a workflow there is some Task that needs to be repeated an unknown number of times. For example, imagine a setup wherein Task A queries a database for a list of all new customers. From here, each customer ID needs to be fed into a Task which “processes” this ID somehow. Within Airflow, there is only one option: implement a downstream Task B which accepts a list of IDs, and loops over them to perform some action. There are major drawbacks to this implementation:
- the UI has no knowledge of this dynamic workload, making it harder to monitor during execution
- if any individual record’s execution fails, the entire task fails
- relatedly, you must implement your own idempotent retry logic, because if you fail and retry halfway through, the system has no way to understand that it should magically skip the first half of the loop
Because this is such a common pattern, Prefect elevates it to a feature which we call “Task mapping”. Task mapping refers to the ability to dynamically spawn new copies of a Task at runtime based on the output of an upstream task. Mapping is especially powerful because you can map over mapped tasks, easily creating dynamic parallel pipelines. Reducing or gathering the results of these pipelines is as simple as feeding the mapped task as the input to a non-mapped task. Consider this simple example in which we generate a list, map over each item twice to add one to its value, then reduce by taking the sum of the result:
This workflow execution contains 10 true Prefect Tasks: 1 for the list creation, 4 for each of the two add_one maps, and 1 for the get_sum reduction. Task mapping provides many benefits:
- the mapping pattern is very easy to specify in your Flow
- each Task is a standalone instance, meaning it can be retried / alerted for individually and independently of all the rest. This means that each dynamic pipeline retains all the state-management benefits of a hand-crafted Prefect Flow.
- each execution of your Flow can spawn a different number of tasks (here we hardcoded the list size, but it could have been anything, or even dynamic!)
- as a first-class feature, the UI also knows how to properly display and report mapped Tasks
Versioned Workflows
It is not enough for code to work.
An important feature of any code-based system is the ability to version your code.
Recall that in Airflow, DAGs are discovered by the central scheduler by inspecting a designating “DAG folder” and executing the Python files contained within in order to hunt for DAG definitions. This means that if you update the code for a given DAG, Airflow will load the new DAG and proceed blindly, not realizing a change was made. If your DAG definitions change or are updated regularly, this leads to a few headaches:
- The ability to revisit or even run your old DAGs requires you to store the old code and names yourself as separate entities in your Airflow ecosystem
- the UI doesn’t know anything about your version system and can’t provide helpful information about versioned workflows
In practice, this means that teams tend to resort to a combination of Github + the old-fashioned method for versioning: appending version information to filenames. Once again, this is not a burden if your workflows truly are slowly changing over time. However, as data engineering has become a fast-paced science, embracing experimentation and frequent updates, if only to deploy new models and parameters, this approach fails quickly.
In Prefect Cloud, we have elevated versioned workflows to a first-class concept. Any workflow can become part of a “version group” for easily tracking and maintaining your history. As always, we have sensible defaults:
- versioning automatically occurs when you deploy a flow to a Project that already contains a flow of the same name
- when a flow is versioned, it gets an incremented version number and any prior versions are automatically archived (which turns off automatic scheduling)
Both of these settings can be customized if you have more complicated versioning requirements. For example, you could specify that any flow is a version of any other flow, regardless of name or project. You could override the automatic version promotion to unarchive and enable old versions (for example, for A/B testing). Or you could use versioning simply to maintain a history of your workflow without polluting your UI.
Local Testing
The major difference between a thing that might go wrong and a thing that cannot possibly go wrong is that when a thing that cannot possibly go wrong goes wrong it usually turns out to be impossible to get at or repair.
Because both Airflow and Prefect are written in Python, it is possible to unit test your individual task / operator logic using standard Python patterns. For example, in Airflow you can import the DagBag, extract your individual DAG and make various assertions about its structure or the tasks contained within. Similarly, in Prefect, you can easily import and inspect your Flow. Additionally, in both Airflow and Prefect you can unit test each individual Task in much the same way you would unit test any other Python class.
However, to test your workflow logic can be significantly trickier in Airflow than Prefect. This is for a number of reasons:
- DAG-level execution in Airflow is controlled and orchestrated by the centralized scheduler, meaning to run a pass through of your DAG with dummy data requires an initialized Airflow database and a scheduler service running. This can be tricky to put into a CI pipeline and for many people is a barrier to testing at this level.
- Airflow’s notion of Task “State” is simply a string describing the state; this introduces complexity for testing for data passage, or what types of exceptions get raised, and requires database queries to ascertain
In Prefect, on the other hand, recall that flows can run themselves locally using flow.run (with retries) or with a FlowRunner for single-pass execution. Additionally, each of these interfaces provides a large number of keyword arguments designed specifically to help you test your flow, critically including a way to manually specify the states of any upstream tasks.
For example, to make sure your trigger logic works for an individual task, you can pass in all upstream task states through the task_states keyword argument; because Prefect returns fully hydrated “State” objects (which include such information as data, exceptions, and retry times), you can easily make assertions on the nature of the returned State for the task of interest.
UI
I want to believe.
One of the most popular aspects of Airflow is its web interface. From the UI, you can turn schedules on / off, visualize your DAG’s progress, even make SQL queries against the Airflow database. It is an extremely functional way to access Airflow’s metadata.
From day one, we designed Prefect to support a beautiful, real-time UI. We didn’t want to follow Airflow’s model of simply exposing database views, but rather take advantage of best practices to immediately surface the answers to our users’ most pressing questions: What is the health of my system; and, if something is wrong, how quickly can I identify it?
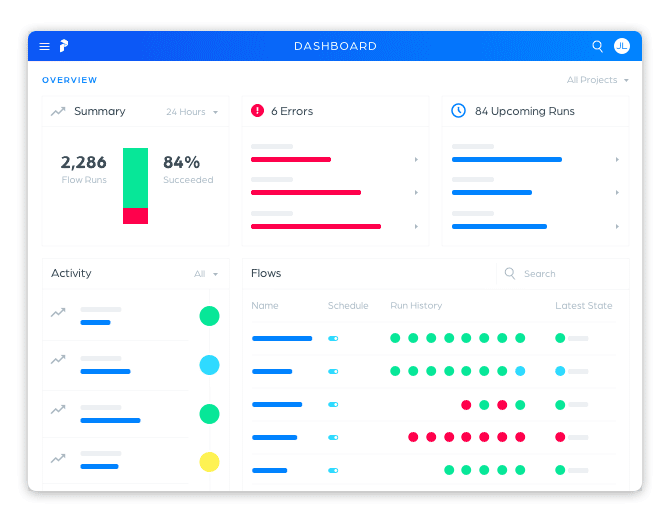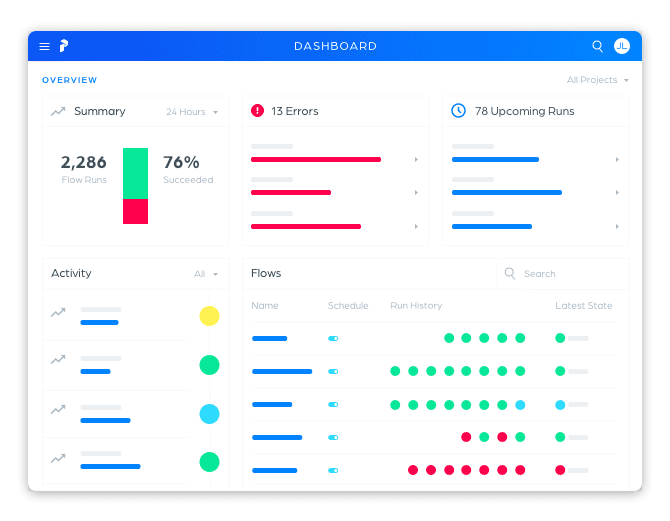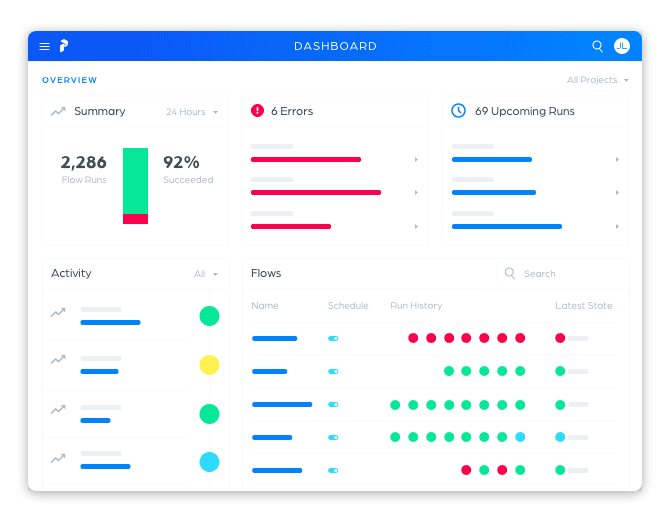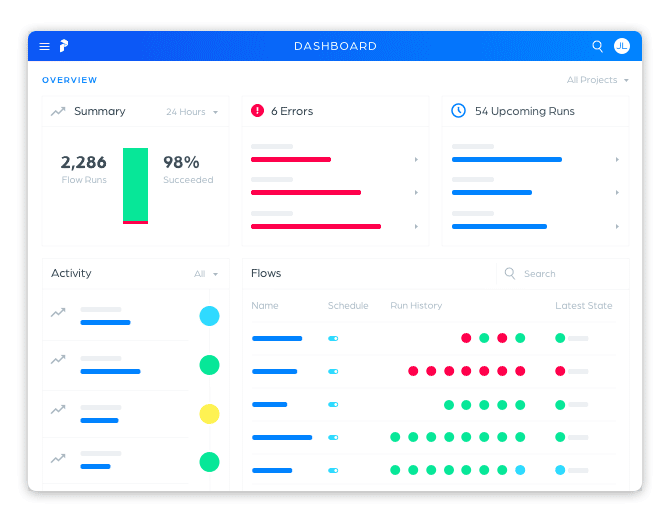
The Prefect UI supports:
- dashboards for system overviews
- scheduling new parameterized runs
- live-updating task and run states
- manually updating states
- streaming logs, including the ability to jump immediately to the latest error log
- a full interactive GraphQL API
- global search
- agent management
- projects for organizing flows
- team management and permissions
- API token generation
- secret management
- global concurrency limits
- timezones (this one’s for you, Airflow users!)
- …and quite a bit more
The UI is part of Prefect Cloud because it is backed by the same infrastructure that allows us to deliver production-grade workflow management to our customers. However, we are committed to making it increasingly available to users of our open-source products, beginning with its inclusion in Cloud’s free tier. We are working on other ways of delivering elements from the UI to our open-source users.
Conclusions
If I have seen further than others, it is by standing upon the shoulders of giants.
Airflow popularized many of the workflow semantics that data engineers take for granted today. Unfortunately, it fails to meet companies’ more dynamic needs as the data engineering discipline matures.
Prefect is a tool informed by real use cases collected from hundreds of users that addresses the changing needs of the industry. It is an engine for enabling arbitrary proprietary workflows, exposing a vocabulary well-suited to a wide variety of data applications.
If you’re curious to learn more, please check out our docs or visit our repo. If you’d like to check out Prefect Cloud, you can sign up for a free account!
Related Content








